앞페이지에서 "자전거 렌탈 데이터"를 가지고 수치예측을 위한 머신러닝 모델을 만들어봤습니다.
Random Forest 라는 알고리즘을 사용해서 학습한 모델이죠.
이렇게 ML(Machine Learning) 알고리즘을 가지고 학습하는 과정을 트레이닝(Training)이라고 합니다.
앞에서 학습하는데 사용한 데이터 "Bike Renting Data.xlsx" 를 트레이닝 데이터라고 하죠.
이번에는 테스트를 할려고 하니, 당연히 테스트용 데이터가 필요합니다.
테스트용 데이터를 일부러 기존꺼 데이터에서 count 값만 빼서 만들어봤습니다. 그러면, 우리가 실제 count 값을 알고 있으니 나중에 얘가 얼마나 잘 맞췄는지 확인해 볼 수 있겠죠? ^^
모델을 적용(Predict) 하는 것도 모델을 만드는 것과 똑같이 "데이터 흐름"을 이용합니다.
테스트데이터를 집어넣고, [생성] - [데이터흐름] 을 눌러서 데이터흐름 화면으로 넘어갑니다.
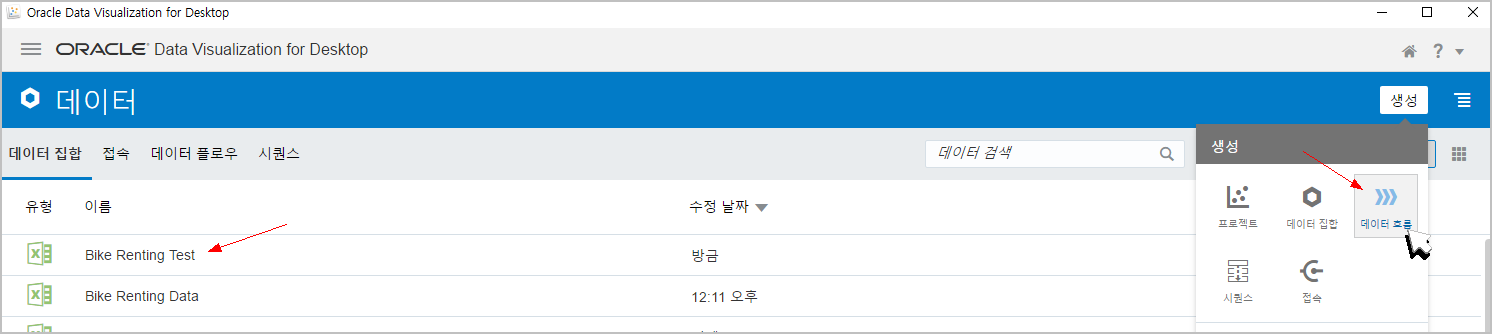
"Bike Renting Test" 데이터를 선택합니다.
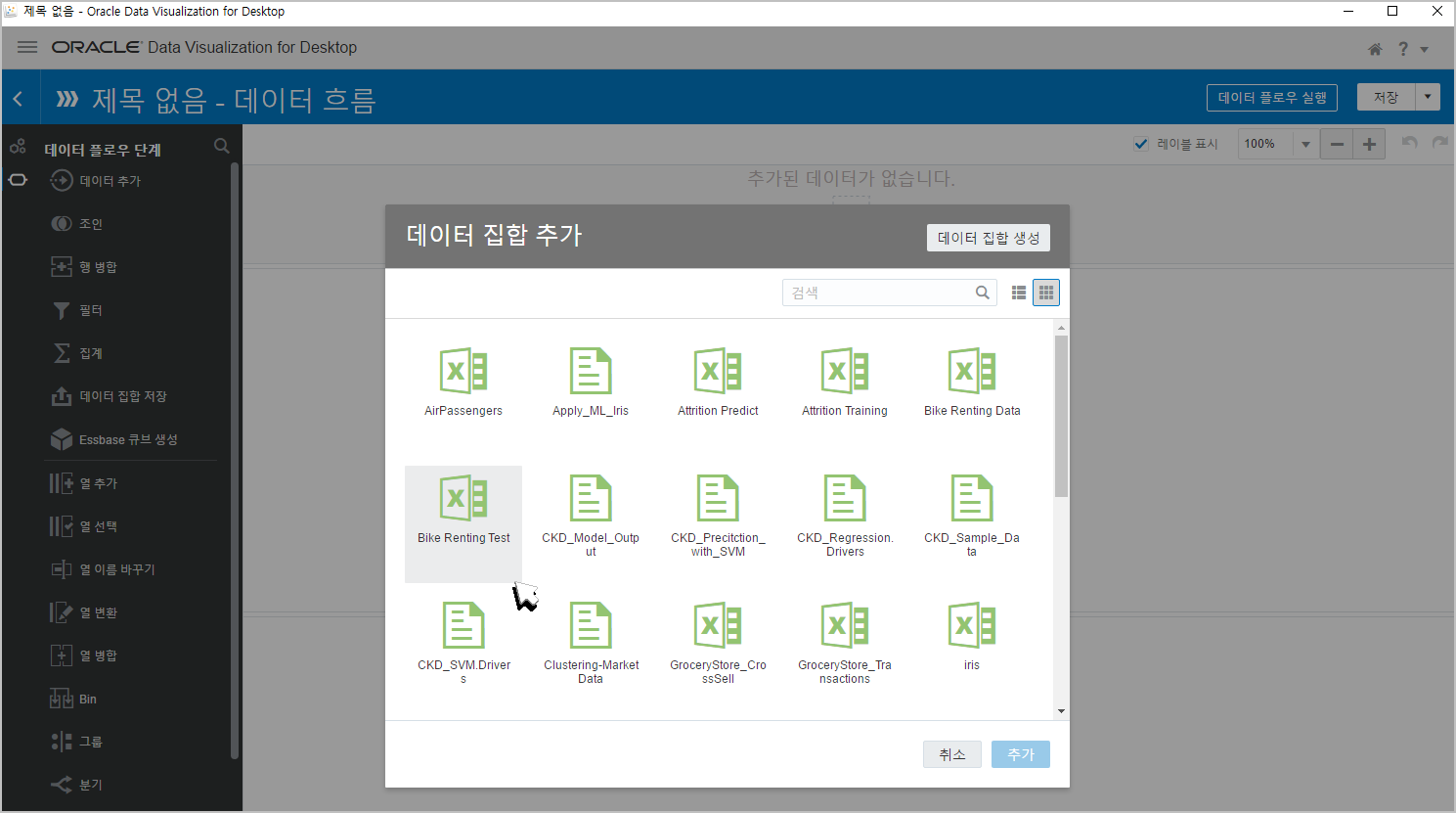
이번에는 [열선택]을 할 필요가 없습니다.
어차피 어떤 컬럼으로 학습을 했는지 모델이 기억하고 있기 때문에 Intant, dteday 컬럼을 제거해주지 않아도 자동으로 제껴줍니다.
바로 우리가 만든 모델을 적용시키면 됩니다. [모델적용] 을 클릭합니다.
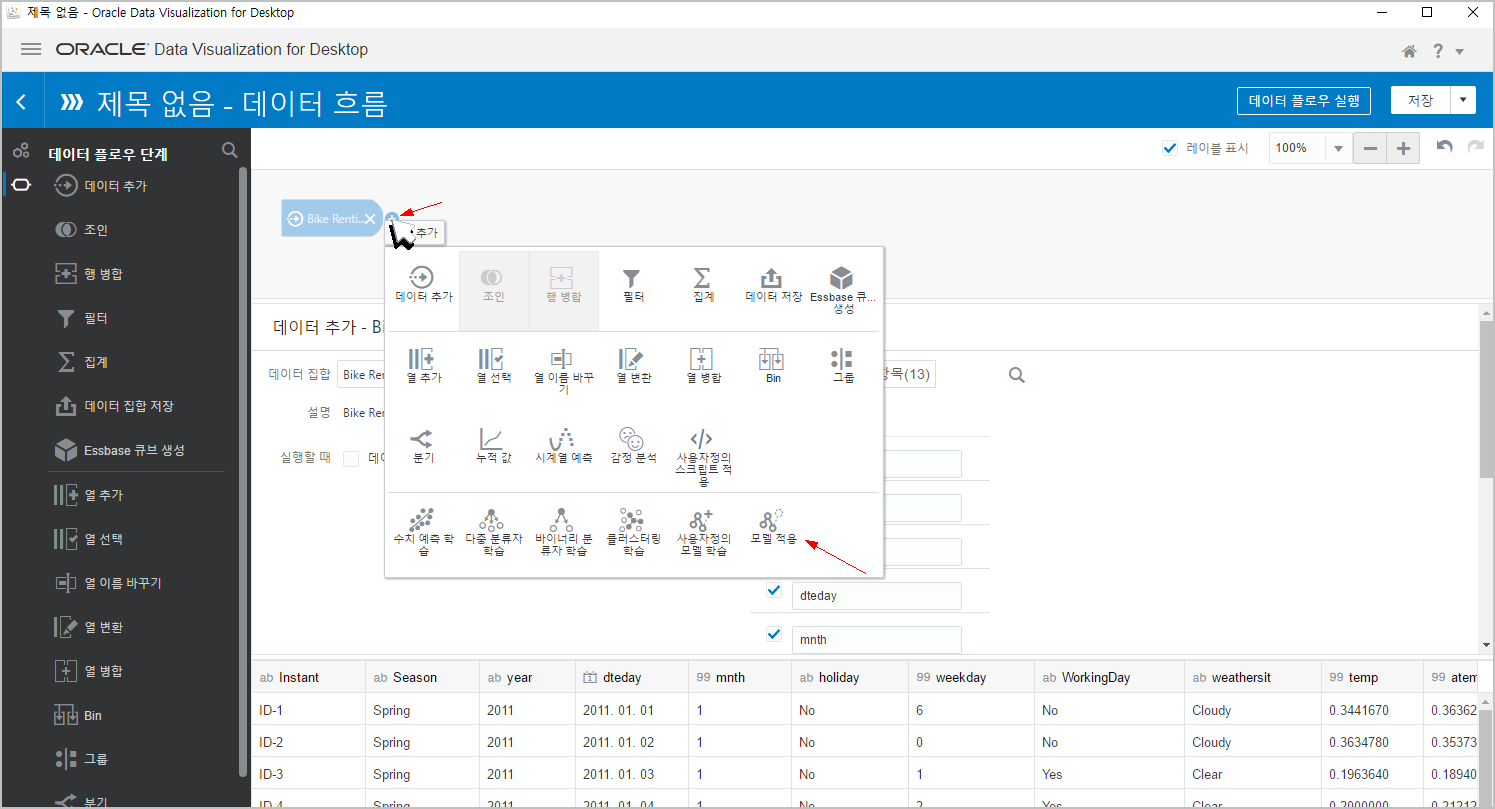
우리가 만든 "ML_Bike_Predict_RF" 를 선택합니다.
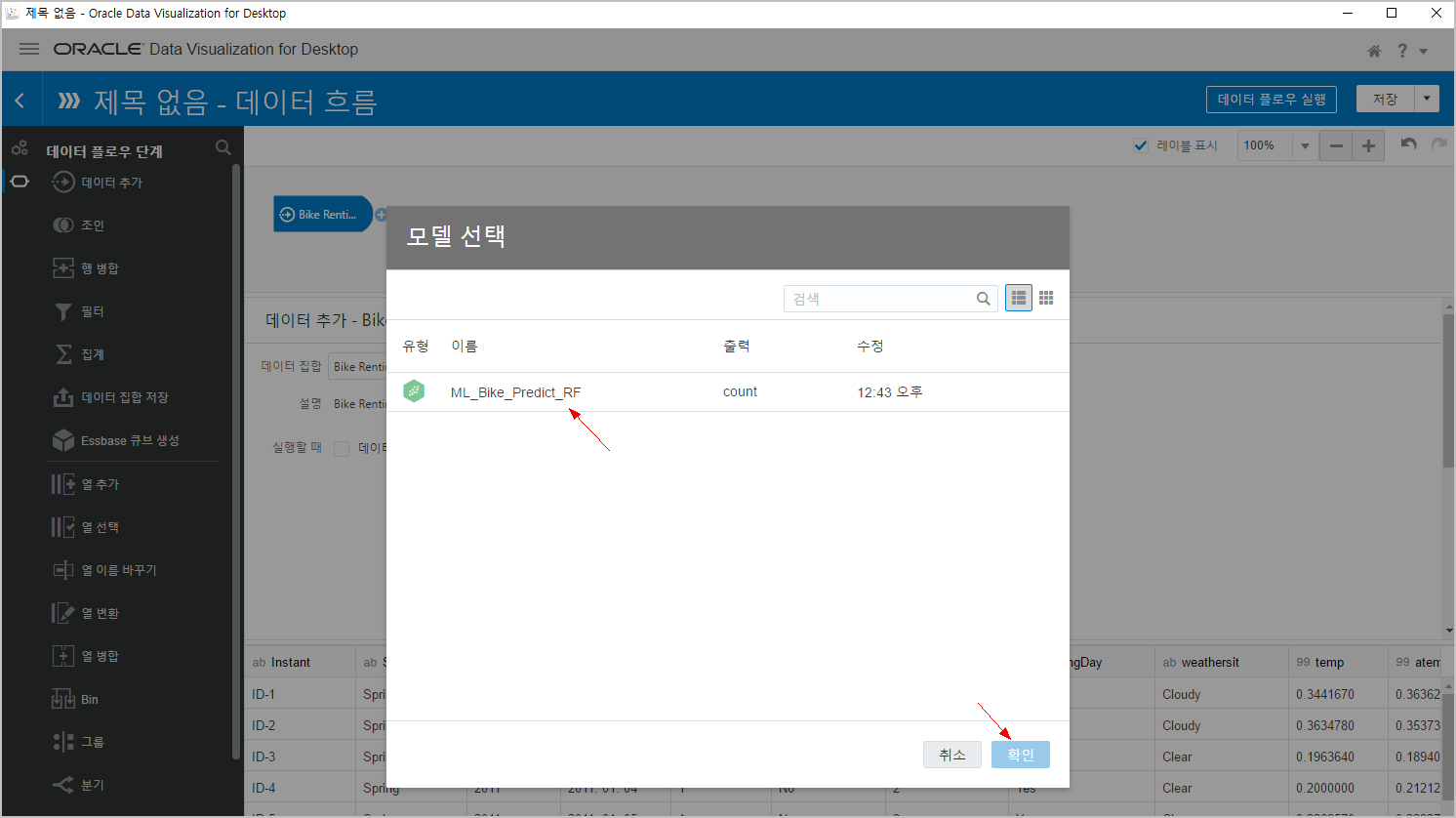
출력 항목에 나오는 PredictedValue 가 우리의 목표값(예측치) 입니다. 예측 자전거 대여건수~
이때 모델에서 사용하는 입력변수를 아래에서 확인할 수 있습니다. 여기에 모델에서 학습할 수 사용하지 않았던 Instant, dteday 컬럼들은 나타나지 않는 것을 확인할 수 있습니다.
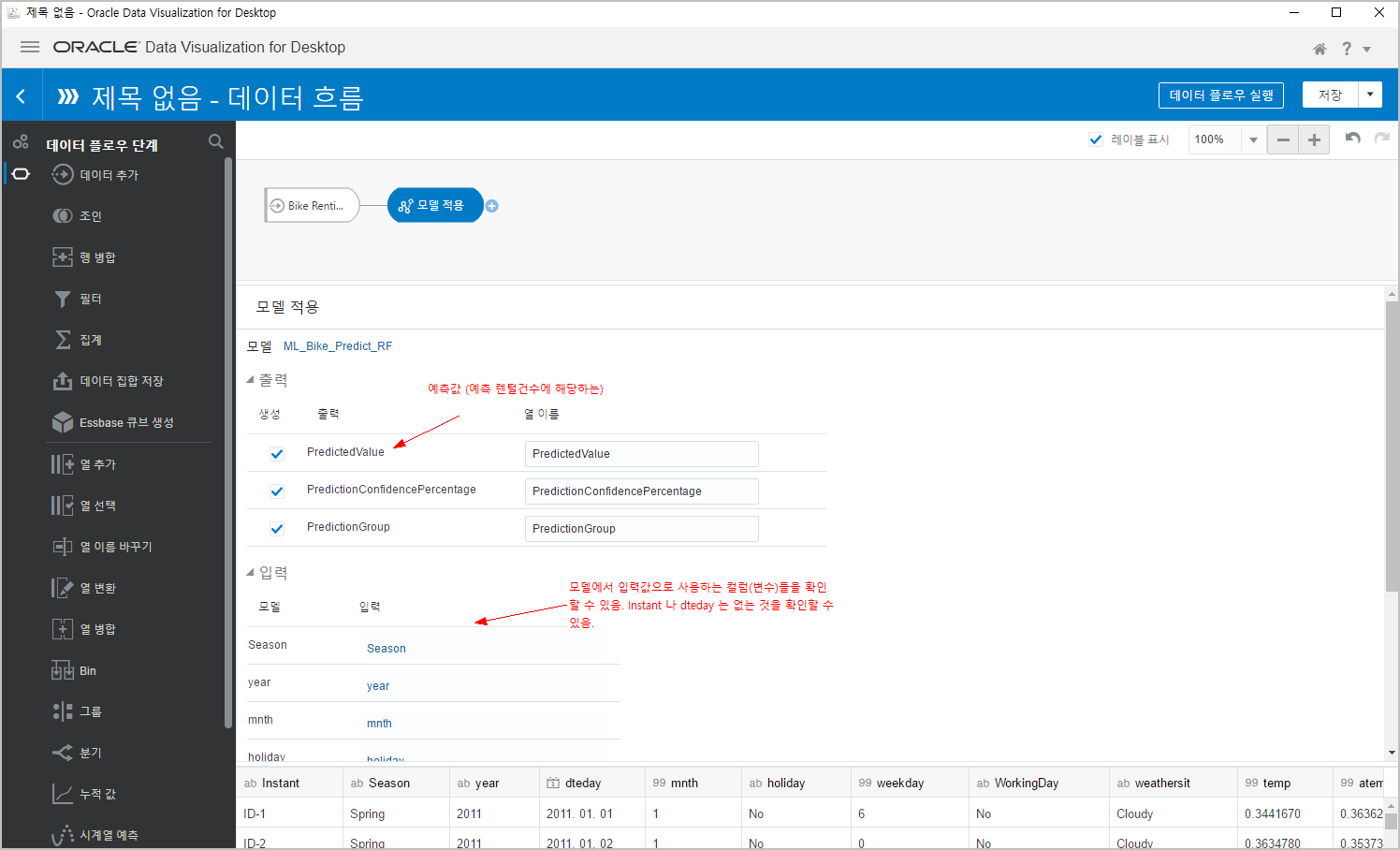
(+) 기호를 누르고, [데이터 저장] 을 클릭합니다.
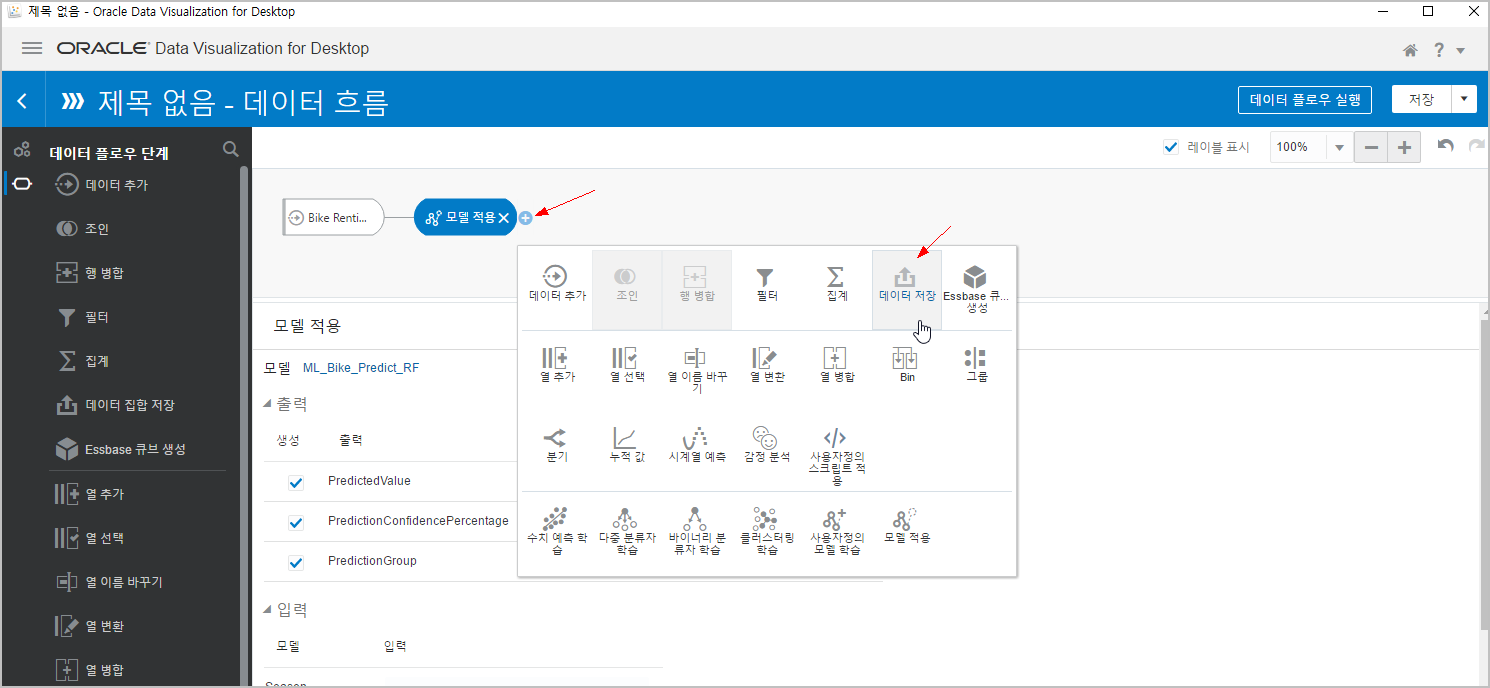
이름을 "Apply_ML_Bike_Predict_RF" 라고 입력하고, [데이터 플로우 실행] 을 클릭합니다.
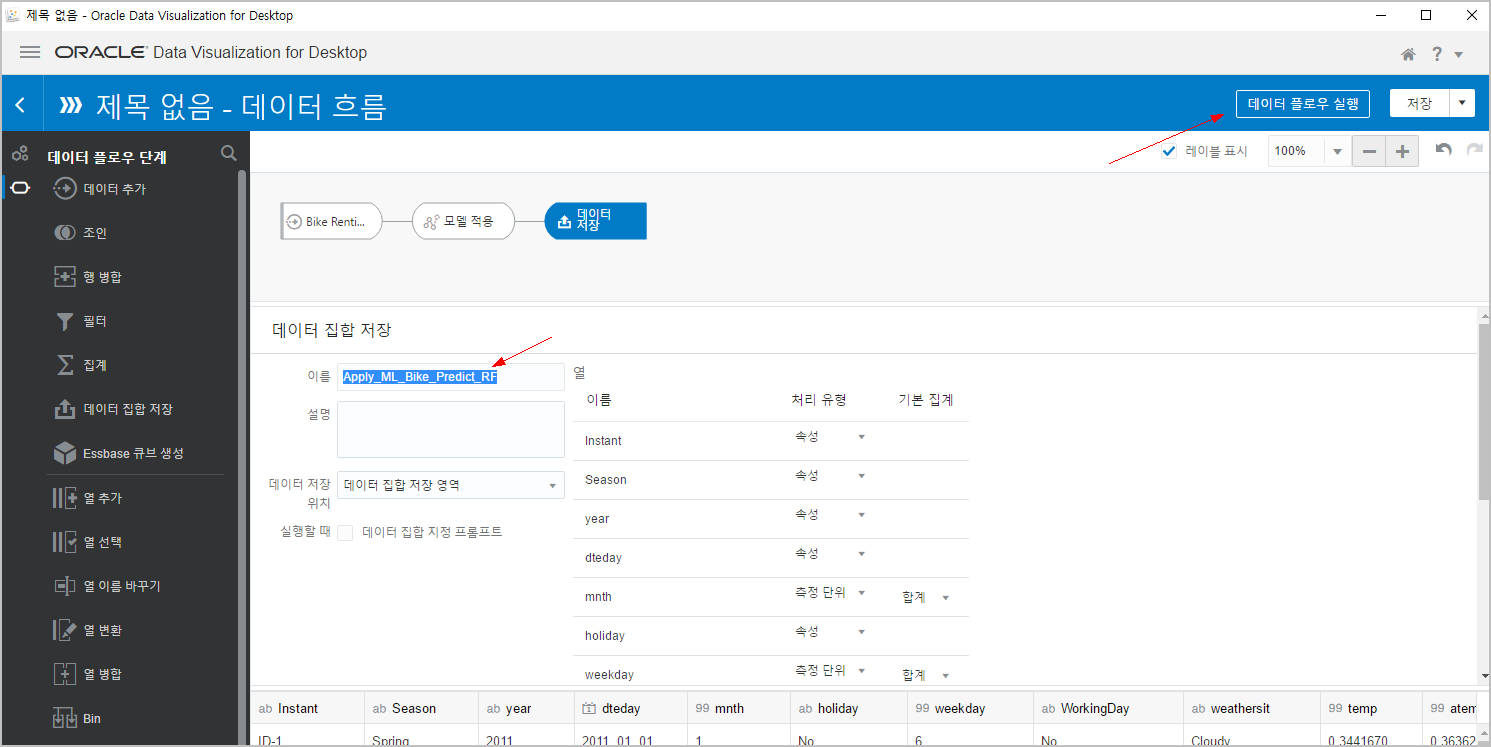
모델이 실행되면 "Apply_ML_Bike_Predict_RF" 이름의 데이터집합으로 결과값들이 생성됩니다.
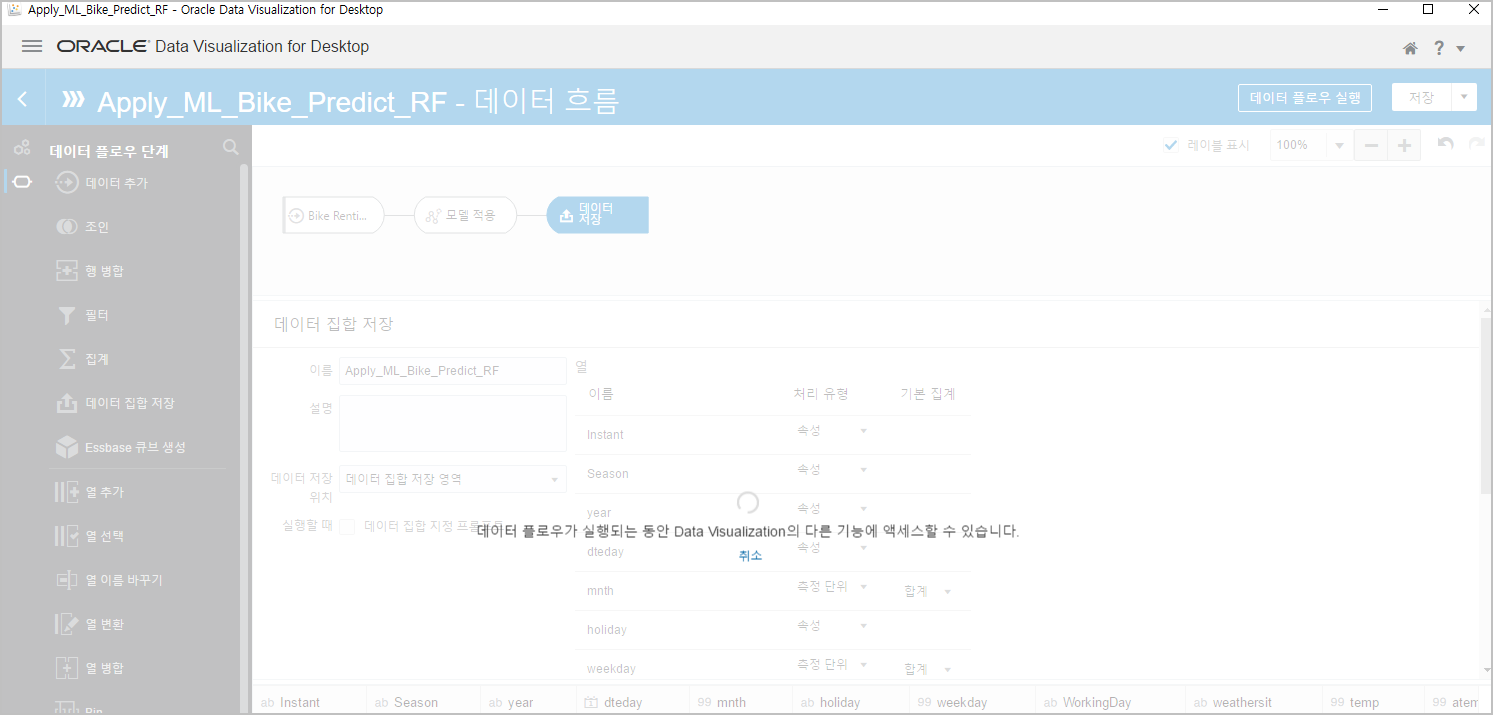
모델 적용(예측)이 완료되면, 좌측 상단의 햄버거버튼(짝대기 세개)를 클릭하여 [데이터] 메뉴를 선택합니다.
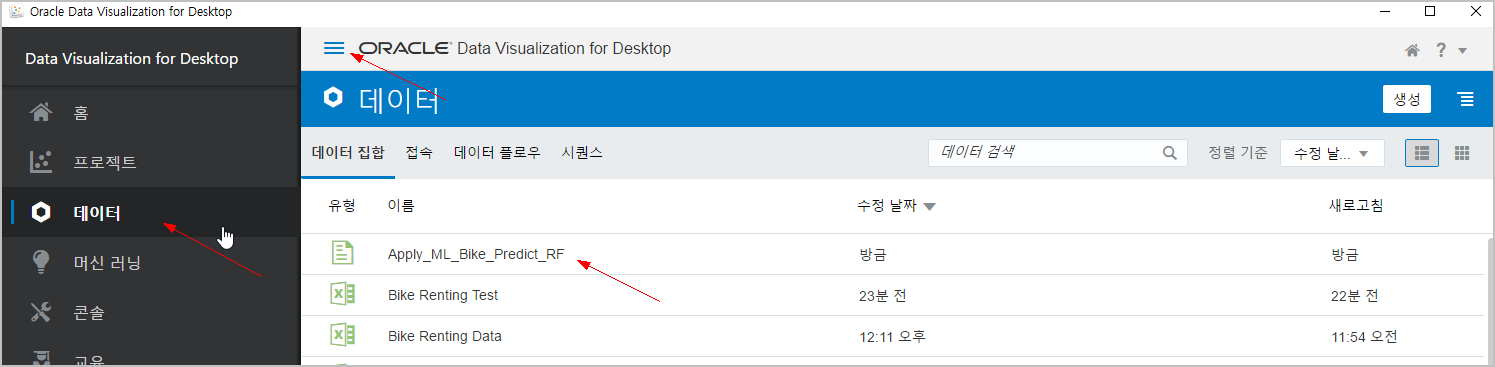
데이터 집합에 "Apply_ML_Bike_Predict_RF" 라는 이름으로 데이터가 생성되어 있는 것을 확인할 수 있습니다.
이제 이걸 클릭하면 바로 프로젝트 화면으로 넘어갑니다.
프로젝트 화면에서 결과값을 확인해보죠~
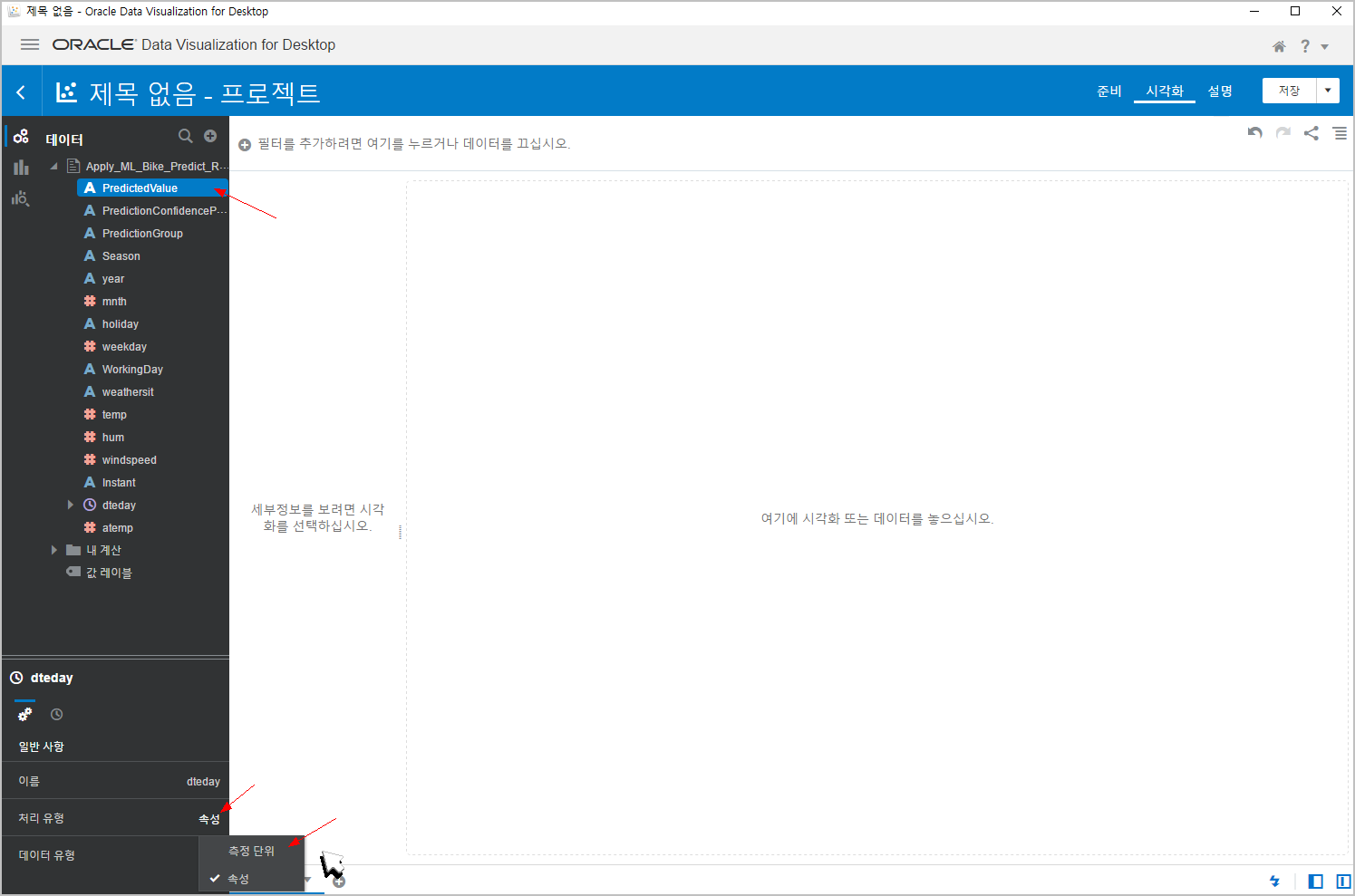
근데, 결과를 확인하기 전에 한가지 해줘야 할게 있습니다.
결과값인 PredictedValue 가 수치데이터여야 하는데, 속성으로 되어 있습니다. 실제값은 수치인데 이게 자동으로 안되네요..
이걸 "측정단위"로 바꿔줍니다.
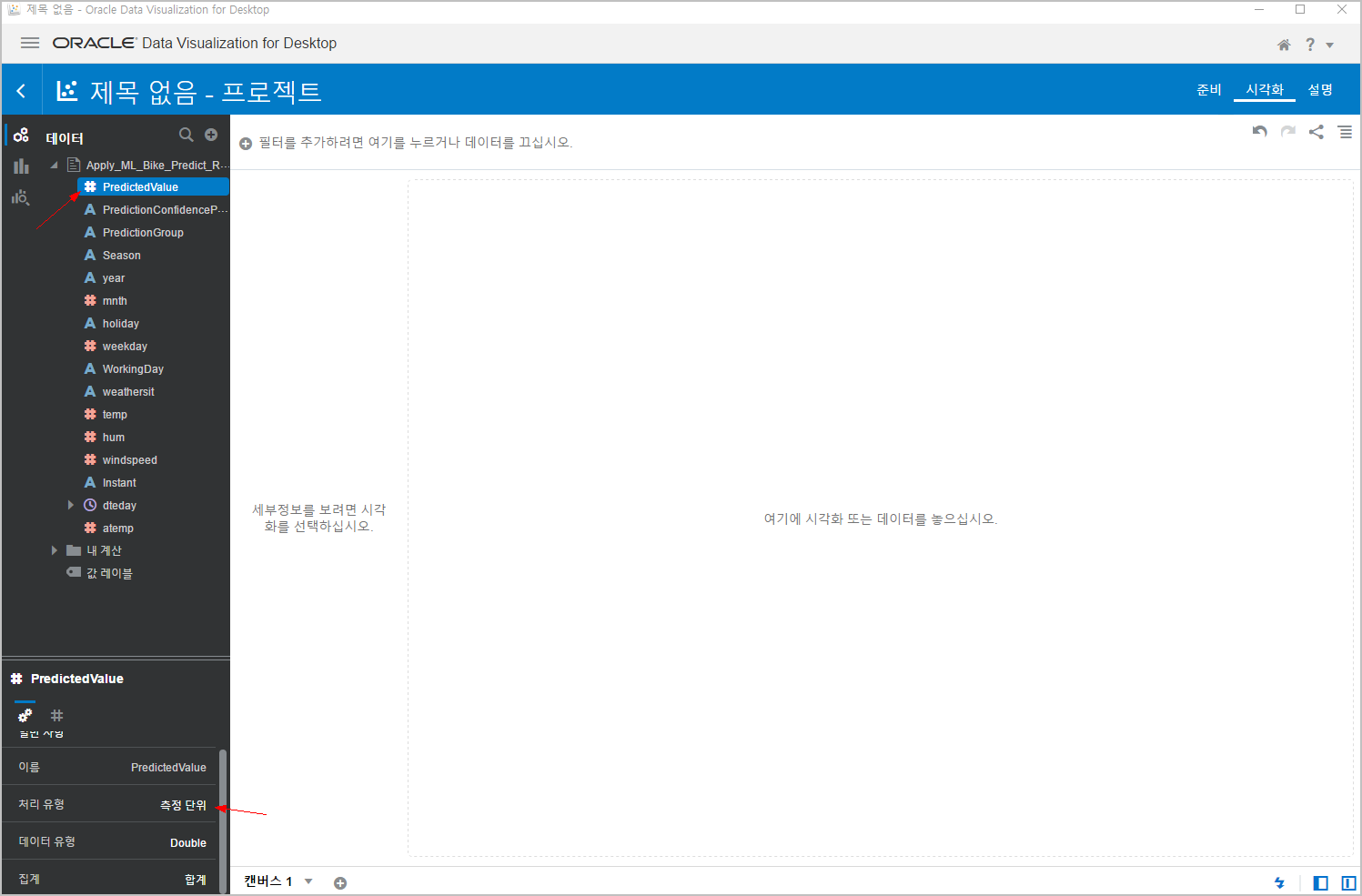
처리유형을 "속성" -> "측정단위" 로 바꾸면, 해당 컬럼 앞에 있는 기호가 "A" -> "#" 으로 바뀌는 것을 확인할 수 있습니다.
DVD에서는 차트상에서 값으로 나타내야 하는 컬럼은 반드시 "#" 기호로 되어 있어야 합니다. 안그러면 차트 표시가 안됩니다.
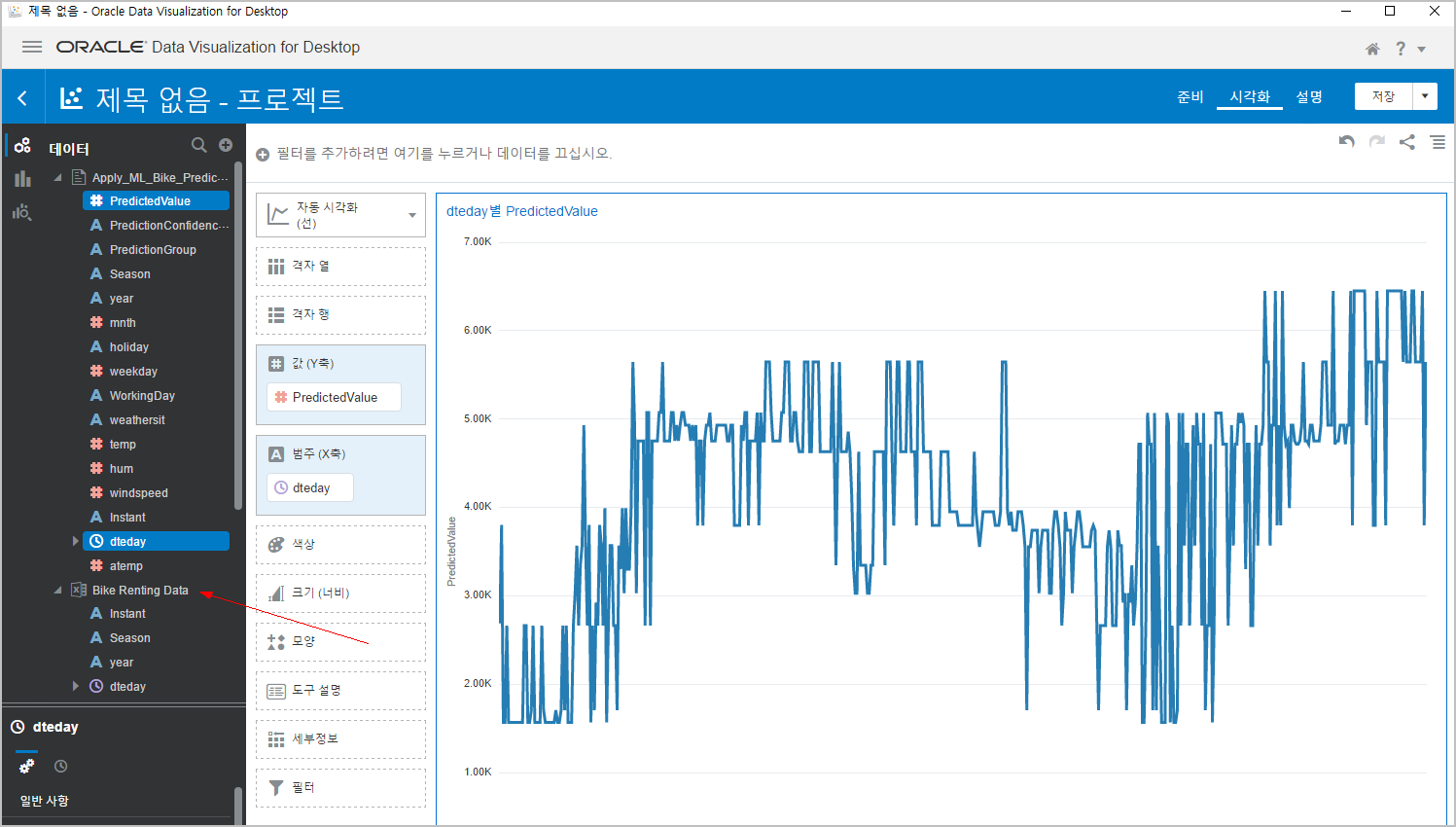
PredictedValue 와 dteday 를 동시에 선택(ctrl키 눌러서)해서 드래그하면 합니다.
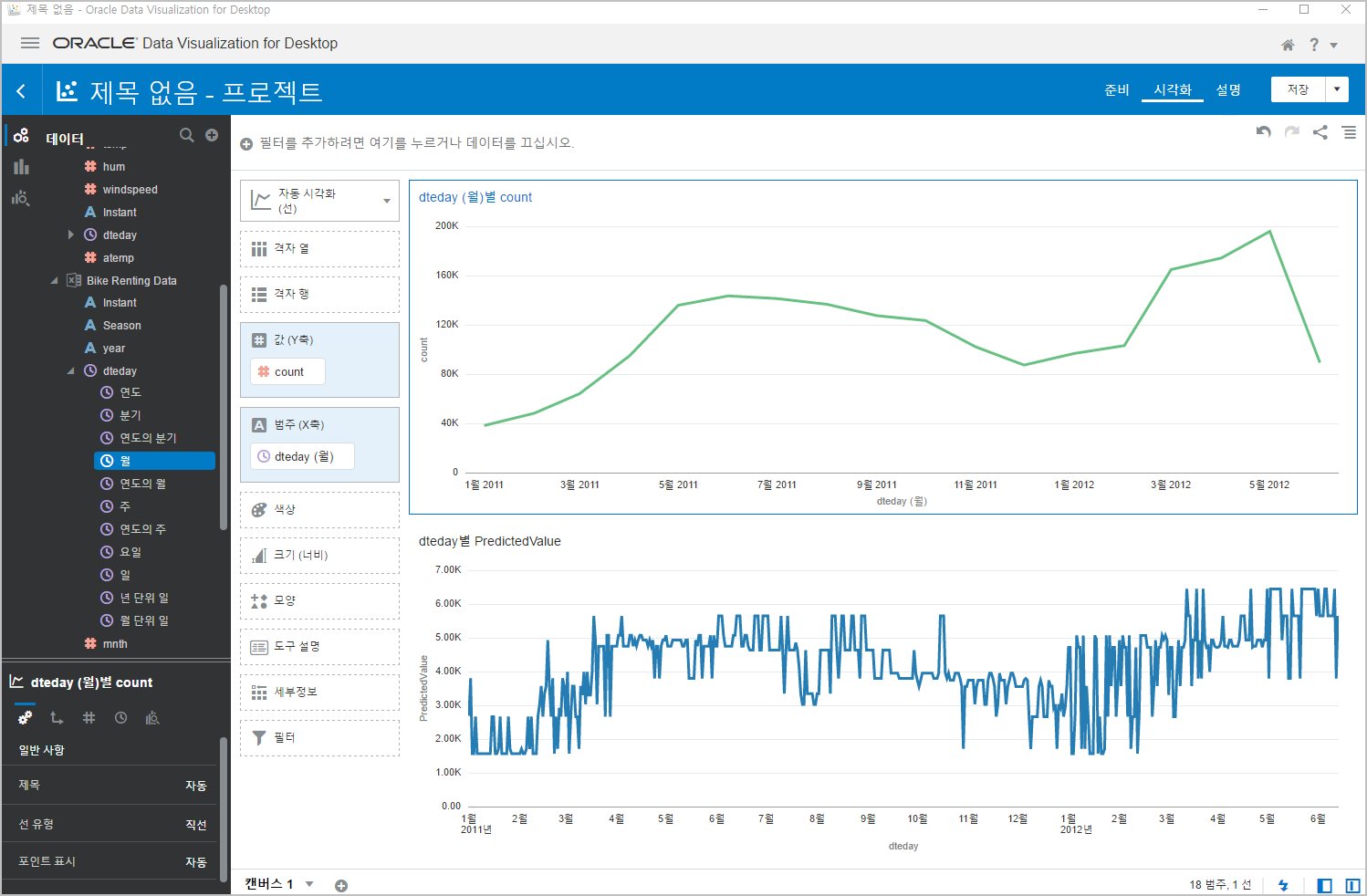
아래와 같이 꺽은선 차트가 만들어집니다.
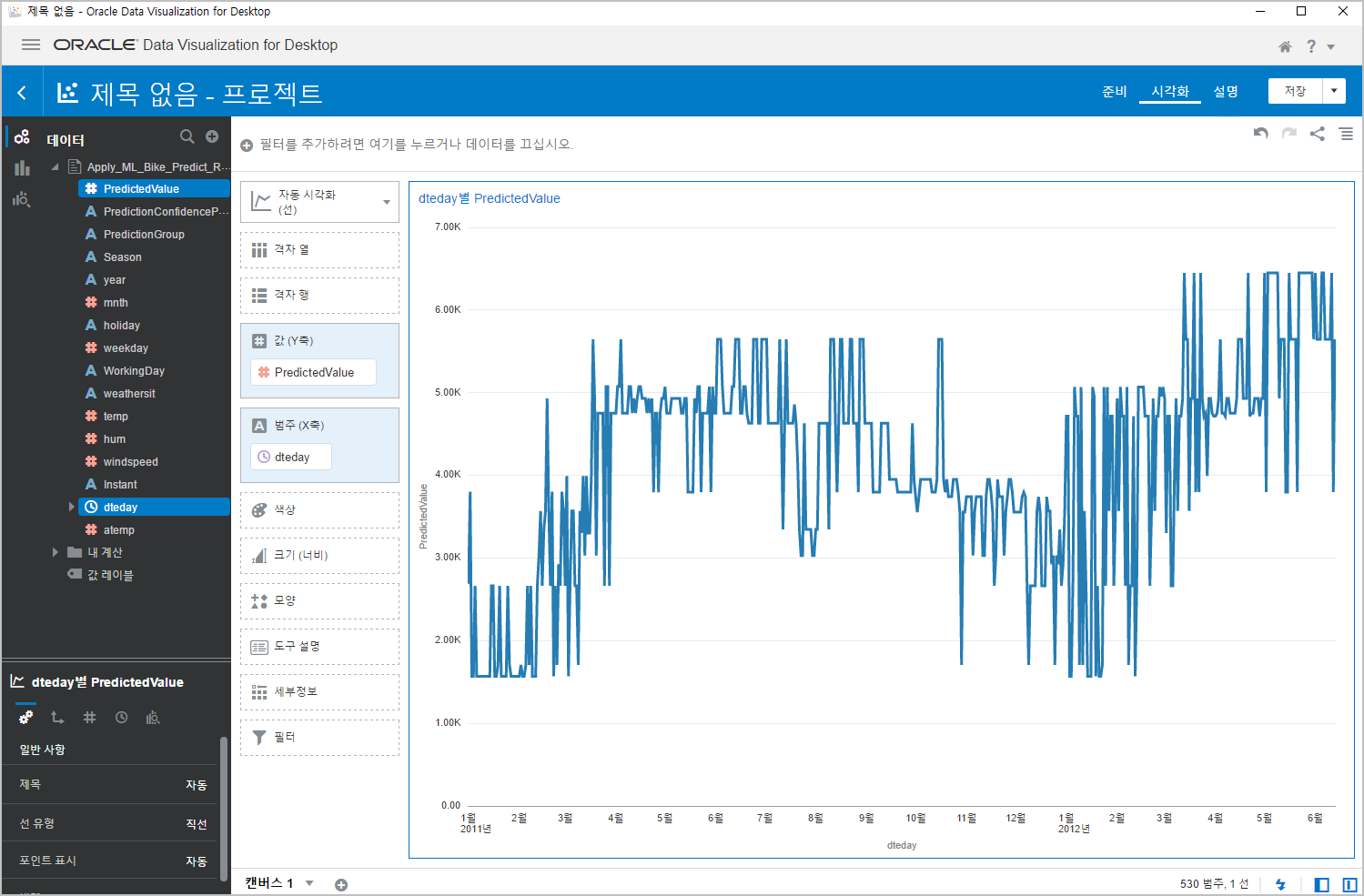
이것이 일자별로 예측한 값이 표시된 겁니다.
우리는 실제값을 알고 있죠 ㅎㅎ
그럼, 실제값으로 똑같이 차트를 그려보면 얘가 얼마나 똘똘하게 맞췄는지 확인해 볼 수 있겠네요.^^
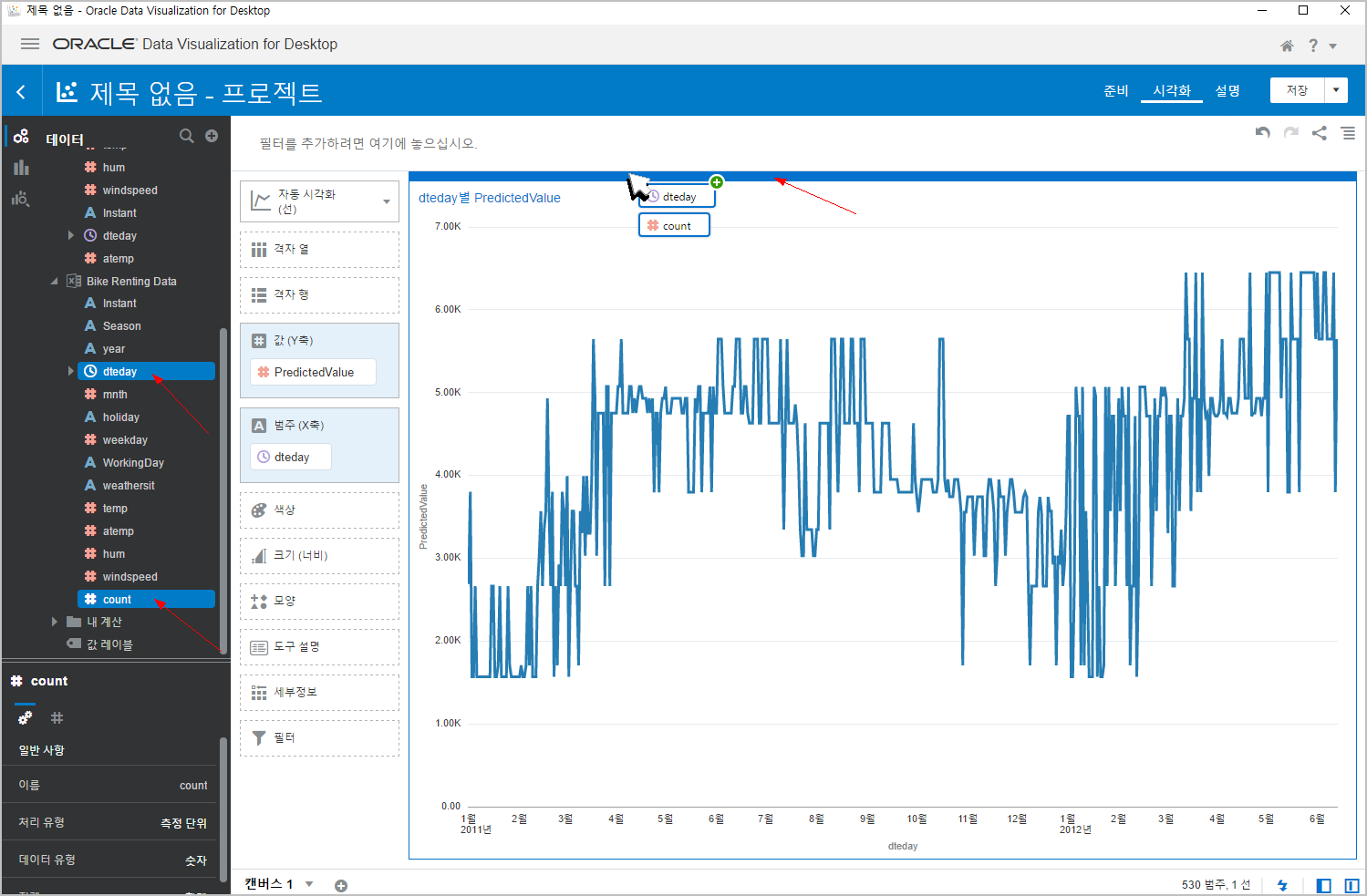
실제값이 들어있는 데이터집합인 "Bike Renting Data" 를 읽어오면 되겠네요.
왼쪽 상단의 (+) 버튼을 누르고, [데이터 집합 추가] 를 클릭합니다.
"Bike Renting Data" 를 선택합니다.
원래 있던 "Apply_ML_Bike_Predic..." 데이터집합 밑에 "Bike Renting Data" 가 추가된 것을 확인할 수 있습니다.
새로 추가된 "Bike Renting Data" 데이터집합에서 dteday 와 count 를 동시에 선택(ctrl키 눌러서)하고 드래그 합니다.
드래그해서 위쪽에 배치합니다. 그러면 기존 차트 위쪽에 새로운 차트가 그려지겠죠?
짜잔~~ 한번 비교해 볼까요?
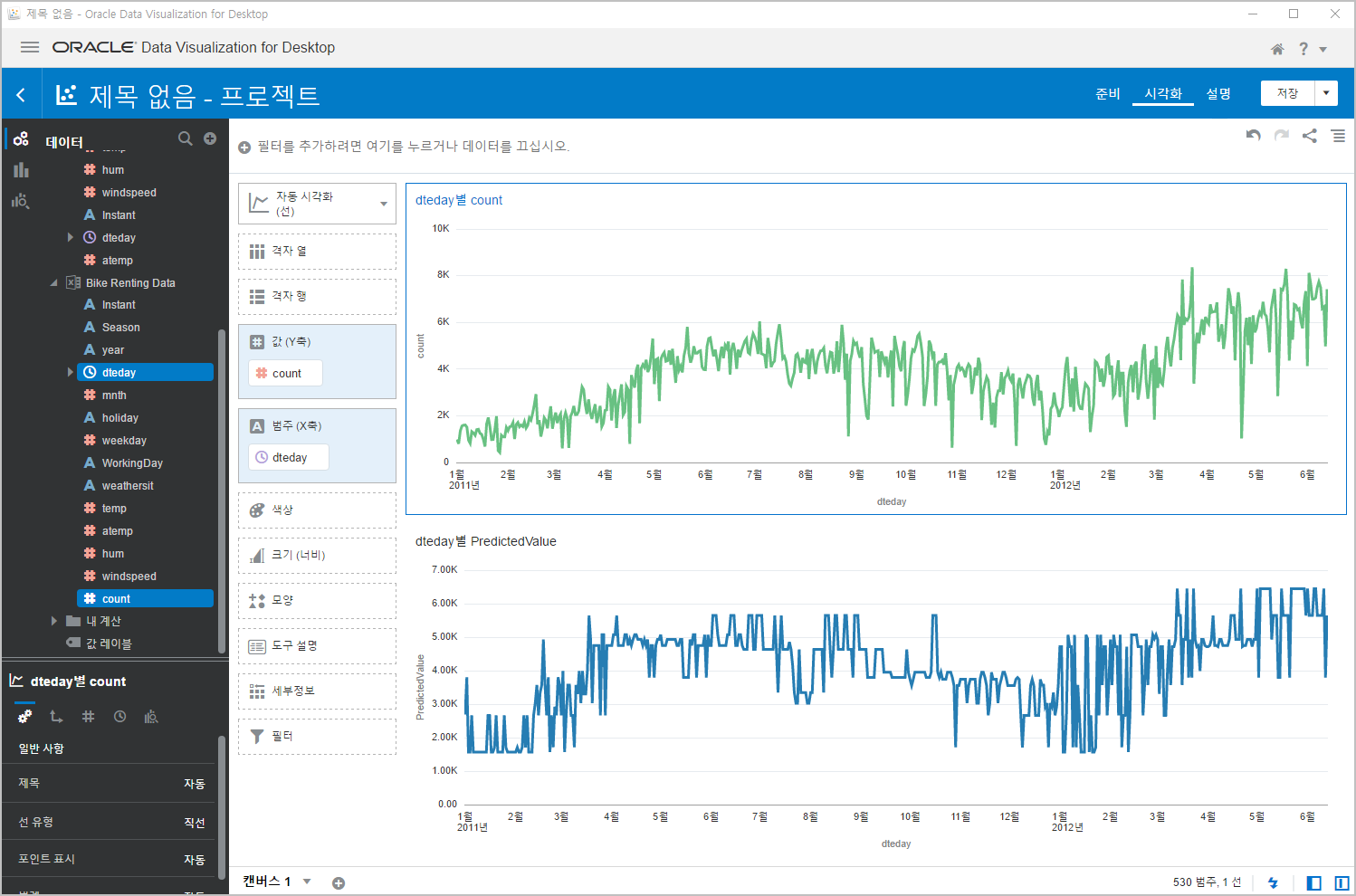
위쪽이 실데이터, 아래쪽이 Random Forest 라는 머신러닝 알고리즘으로 학습후 예측한 값입니다.
얼추 비슷하네요^^
자세히 뜯어보면, 조금씩 많이 미쓰한 것도 보이긴 하지만, 대체적으로 잘 맞추었다고 생각됩니다. 제눈에는^^
이걸 한번 월별합계 차트로 볼까요? 그럼, 더 비슷해보일 것 같은데요...
dteday 컬럼을 클릭해보면 날짜 타입인 경우 연도/월/주/일... 등으로 분해해서 볼 수 있습니다.
"월" 을 선택하고 드래그 해서 기존 "범주(X축)" 에 있는 dteday 위치에 갖다 놓으면 바꿔치기를 할 수 있습니다.
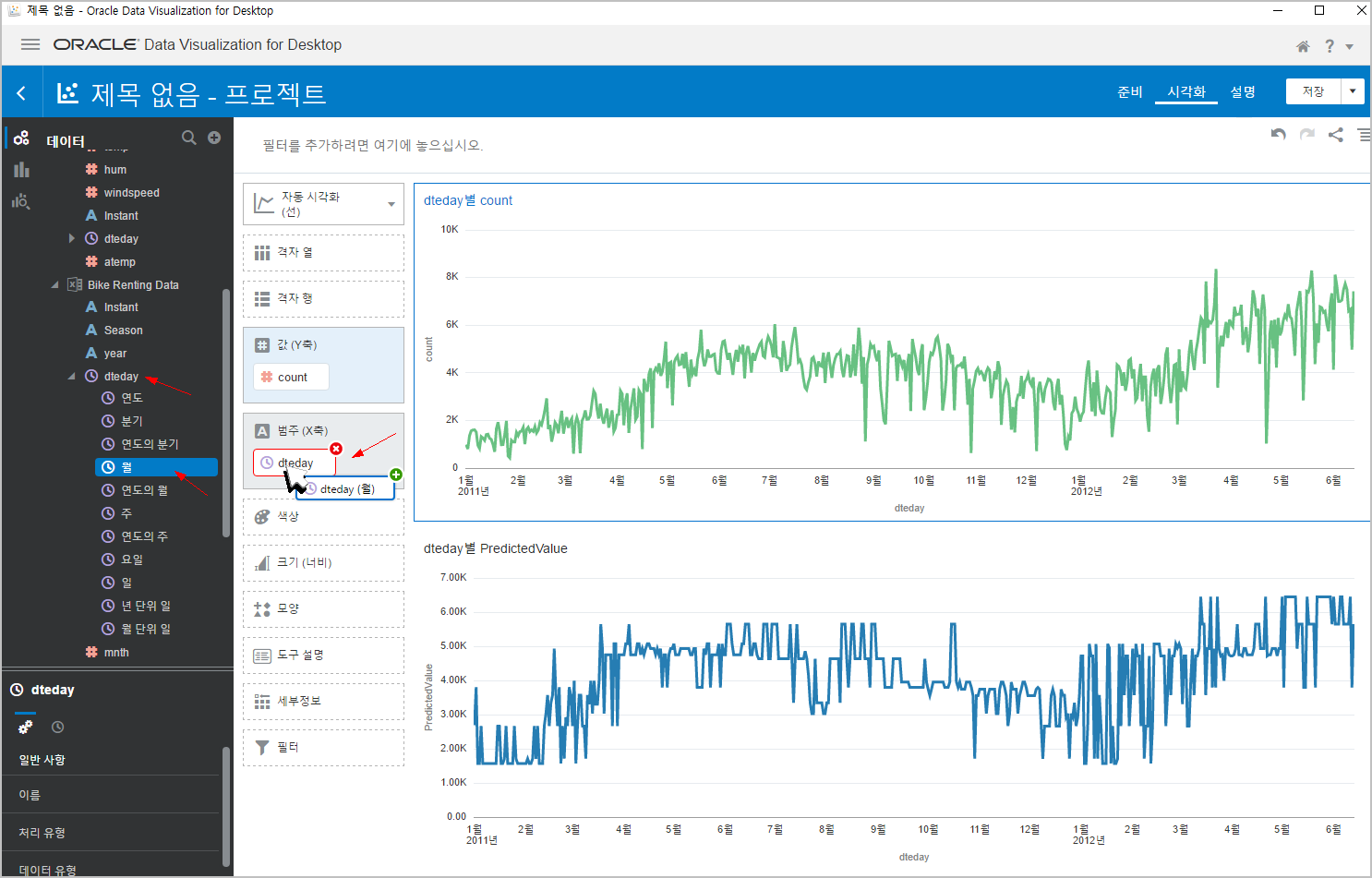
그러면, 아래와 같이 월별 차트로 바뀝니다.
같은 방법으로 아래 차트도 바꾸면, (먼저 아래 차트를 선택후, 월을 드래그 합니다.)
짜잔~~
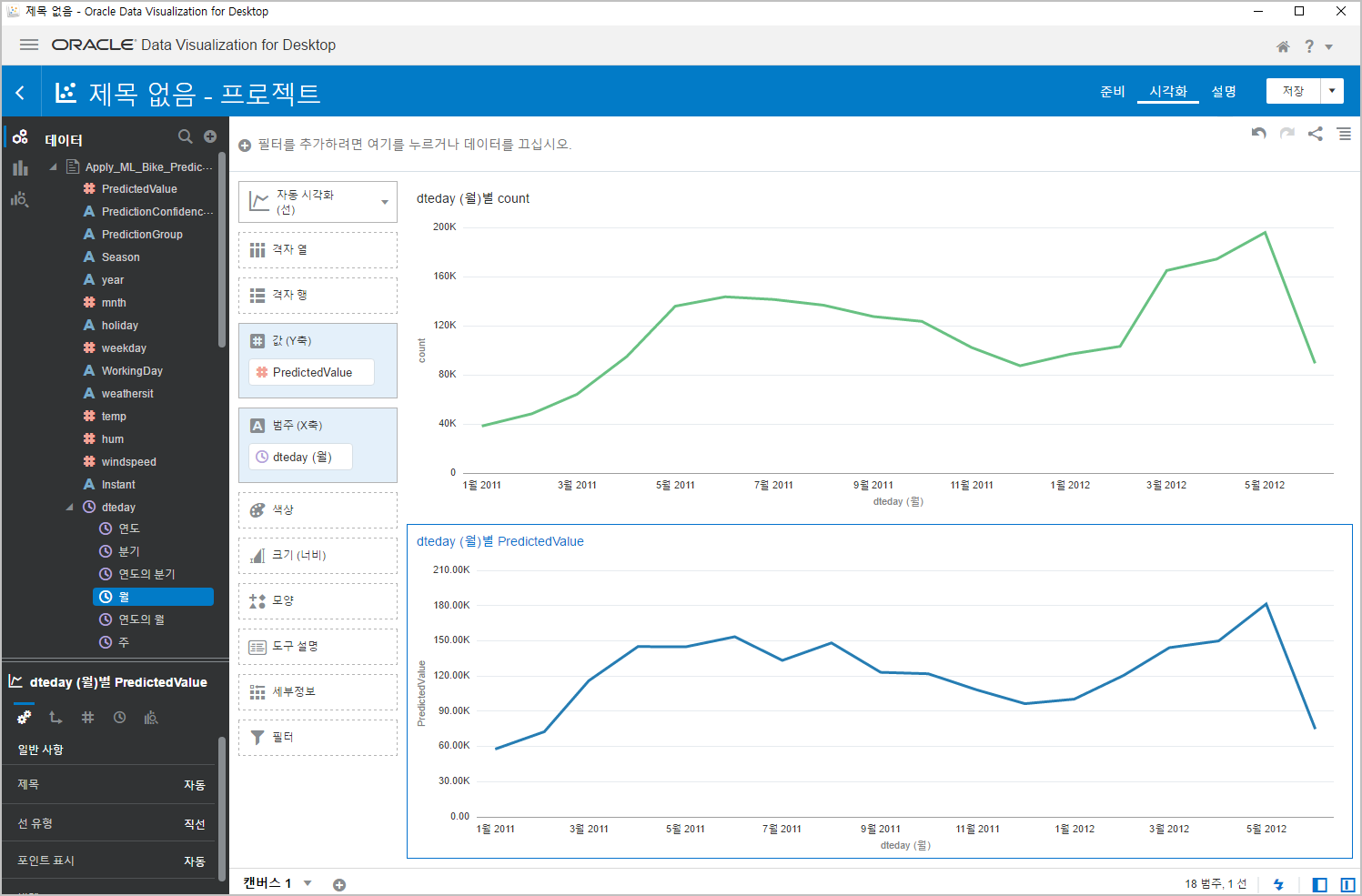
우왕~ 월별 차트로 보니까 더 정확해 보이네요 ^^
이 정도면 쓸만 한데요.
이제 그날 그날 온도, 습도, 바람세기 등만 알면, 오늘 사람들이 자전거를 몇대나 대여해갈지 예측할 수 있겠는데요?
와우~ 언빌리버블^^
잠깐, 앞에서 머신러닝 알고리즘이 4개가 있었는데, 이중에서 한개만 사용해봤습니다.
만약, 4개를 모두 이런식으로 해보면,,,, 그러면 분명 그중에서 보다더 정확한 놈이 있을테고...
그놈을 사용하면 더 정확한 예측이 가능하겠군요. \(#ㅡ_-)/ 앗싸~
'IT관련' 카테고리의 다른 글
| db file scattered read 와 direct path read 의 차이 (0) | 2019.05.27 |
|---|---|
| RMAN 관련 DB 파라메타 (0) | 2019.05.26 |
| DVDesktop에서 머신러닝 실습 (수치 예측) - 모델 만들기 (0) | 2019.05.26 |
| 오라클 Oracle Analytics Desktop (구 DVDesktop) 다운로드 방법 (1) | 2019.05.25 |
| 내컴 똥컴 확인 방법, CPU 벤치마크 (0) | 2019.05.19 |


