지난번에 SQL*Plus 상에서 클러스터링(Clustering) 실습을 해봤습니다.
참조 => >>SQL*Plus 에서 클러스터링(Clustering) 실습<<
이번에는 똑같은 클러스터링을 SQL Developer 에 있는 Data Miner 를 이용해서 해보도록 하겠습니다.
SQL Developer 에서 Data Miner 를 이용하기 위해서는 몇가지 준비과정이 필요합니다. 그건 아래 참조바랍니다.
참조 => >>SQL*Developer 에서 데이터마이닝 준비작업<<
클러스터링은 수학적인 알고리즘(머신러닝 알고리즘)으로 데이터를 자동으로 분류해주는 기법을 말합니다.
데이터에 들어있는 여러가지 속성들을 파악해서 최대한 속성차이가 많이 나도록 분류해주는 게 관건입니다.
SQL*Plus 상에서 클러스터링 실습을 이미 했다면, 아래 데이터 Import 하는 과정은 생략하면 되겠습니다.
아래에 테스트에 사용할 데이터를 첨부합니다.
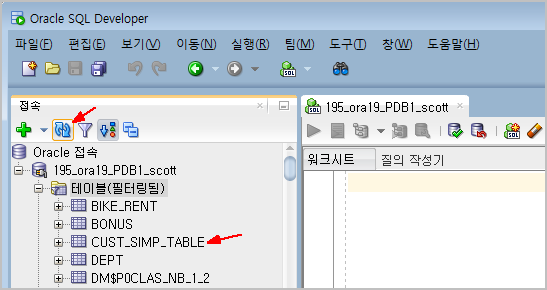
SQL*Developer 에서 아래 파일을 똑같은 이름(CUST_SIMP_TABLE)의 테이블로 Import 합니다.
SQL*Developer 에서 파일을 Import 하는 방법은 여길 참조하세요.
참조 => >>SQL*Developer 에서 테이블 Import/Export 하는 방법<<
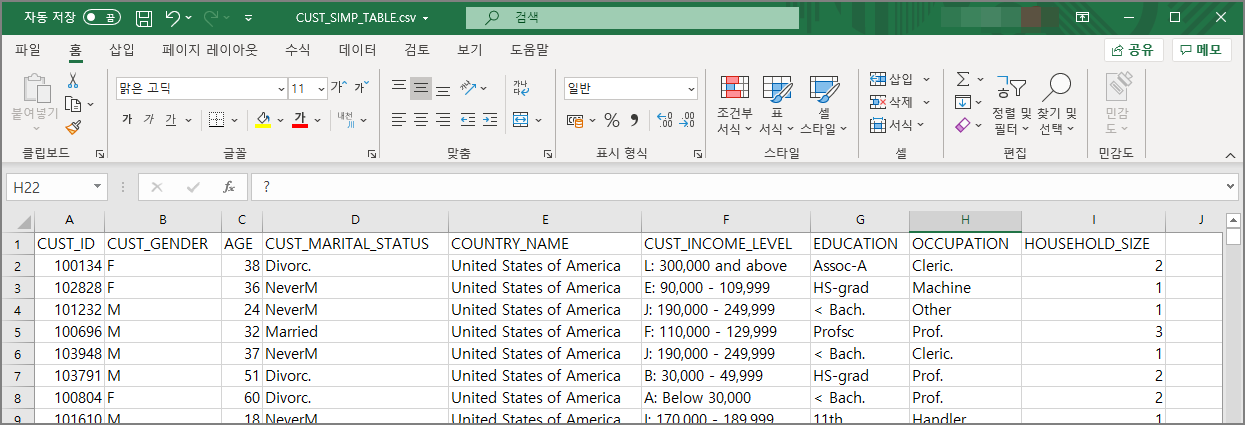
총 9개의 컬럼, 4500건의 레코드로 되어있습니다.
SQL*Developer 에서 Import 한 후에 Refresh 해서 CUST_SIMP_TABLE 이 잘 들어갔는지 확인합니다.
CUST_SIMP_TABLE 테이블 9개의 컬럼중에서 CUST_ID (고객ID)를 제외한 나머지 8개가 이 고객의 속성(Attribute)에 해당합니다. 이 8개의 속성의 차이를 가지고 4500건의 데이터를 Clustering 하는 것입니다.
자, 이제 모든 준비는 되었습니다. 이제 Clustering 을 해보겠습니다.
1) 데이터소스 선택
위에서 "데이터마이닝 준비작업" 을 따라서 잘 했다면, 아래와 같은 화면이 나올 겁니다.
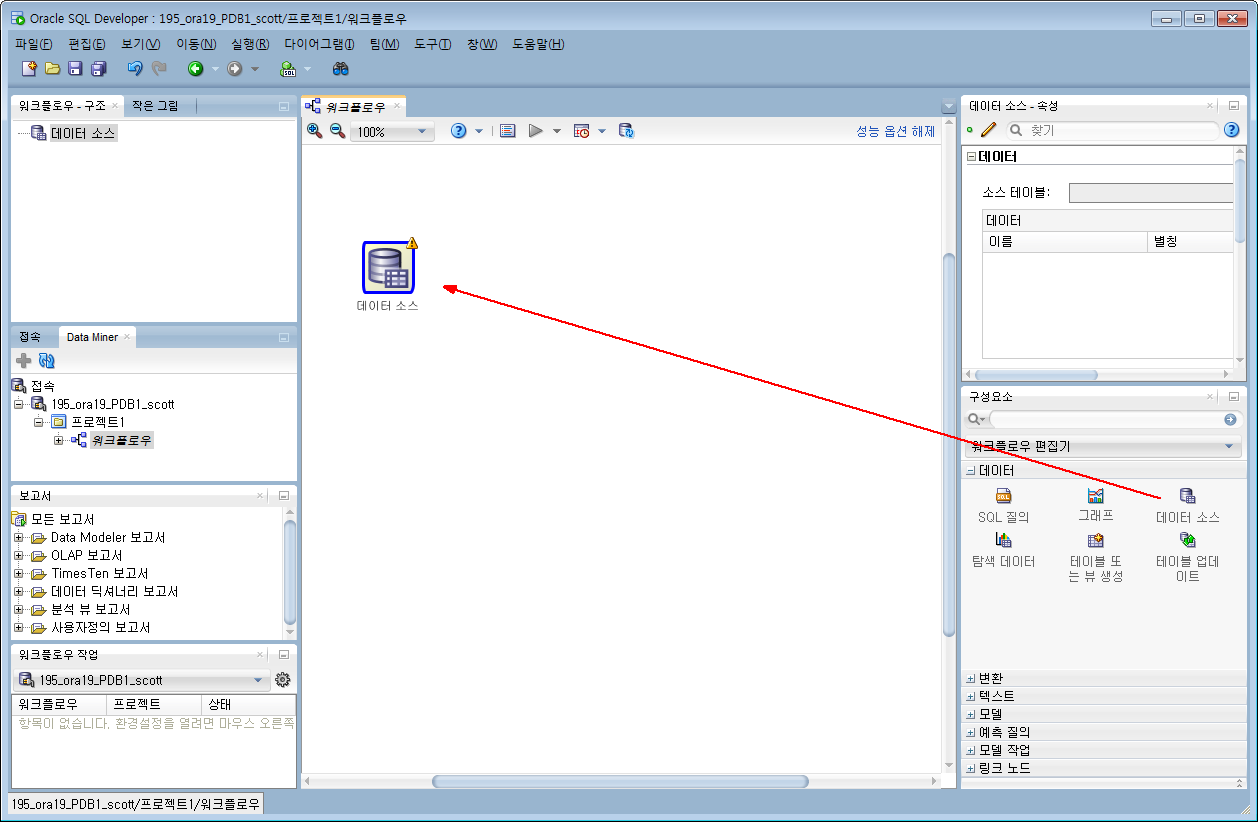
Data Miner 화면 오른쪽 [구성요소] 창에 사용할 수 있는 기능들을 표시됩니다.
맨먼저 할 일은 분석할 데이터를 선택하는 것이겠죠. "데이터소스" 아이콘을 마우스로 Drag&Drop 해서 워크플로우 창에 갖다 놓습니다.
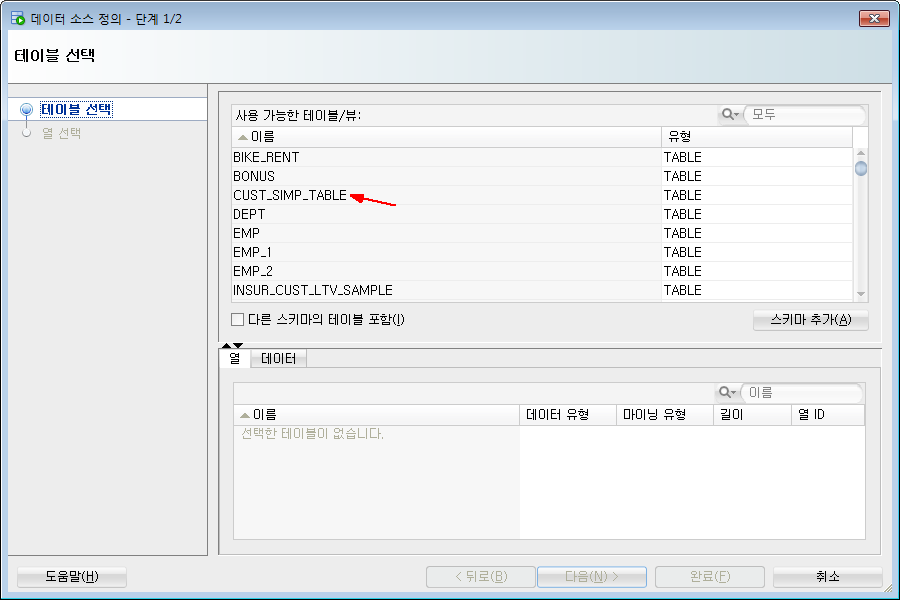
그러면, 아래와 같이 [테이블 선택] 팝업창이 뜹니다.
여기에서 분석할 데이터 소스 (분석할 테이블) 를 선택하는 것입니다.
CUST_SIMP_TABLE 을 선택하고, 하단에 있는 [다음] 버튼을 클릭합니다.
[열 선택] 창으로 넘어갑니다.
선택한 CUST_SIMP_TABLE 테이블에 있는 컬럼들중 분석에 사용하지 않은 컬럼들이 있으면 여기에서 제외해주면 됩니다.
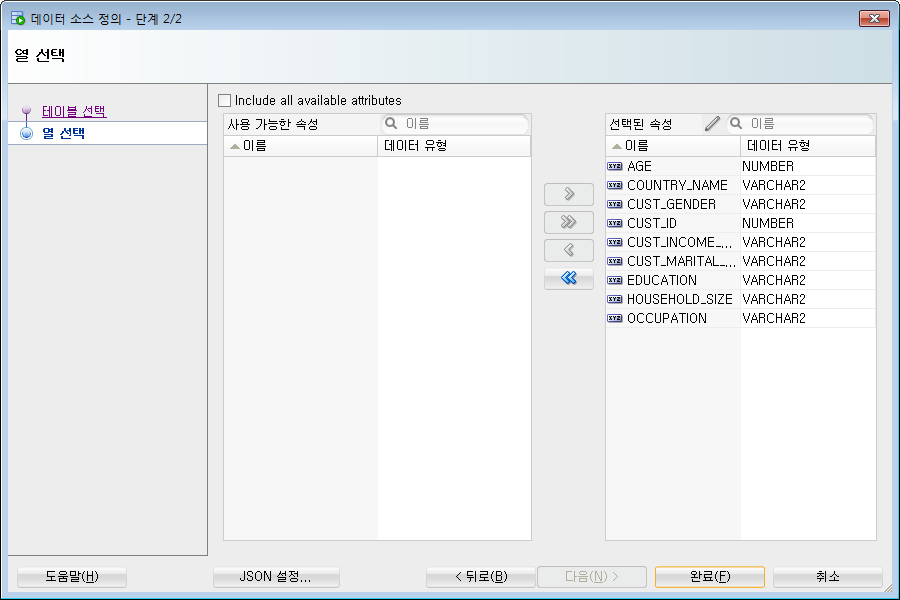
우리는 모든 컬럼을 다 사용할 것이기 때문에 [완료] 버튼을 클릭해줍니다.
2) 분석 모델 선택
이제 분석할 데이터는 준비가 되었고, 분석모델을 선택합니다.
Data Miner 화면 오른쪽 [구성요소] 창에서 [모델] 탭에 있는 [클러스터화] 아이콘을 Drag&Drop 해서 가운데로 가져옵니다.

이제, "데이터소스" 와 "분석모델" 을 연결시켜줘야 합니다.
워크플로우창에 배치된 "데이터소스" 아이콘을 오른쪽 마우스버튼을 클릭하면 아래와 같은 팝업창이 뜹니다.
이 팝업창에서 [접속] 메뉴를 클릭합니다.
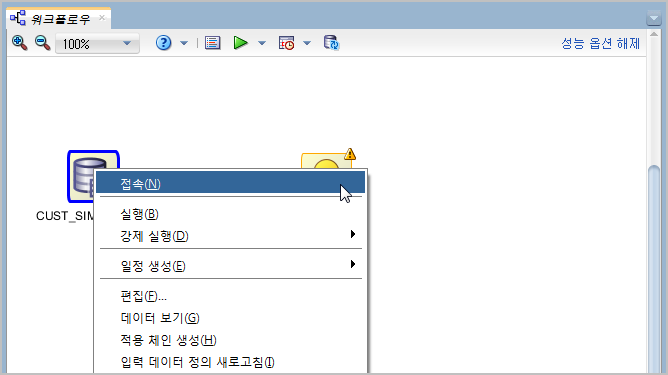
[접속]을 클릭하는 순간 CUST_SIMP_TABLE 로부터 화살표가 나와서 마우스를 따라 다닙니다.
이 화살표를 "클러스터생성" 아이콘에 놓고 클릭해주면 아래처럼 연결(접속)이 됩니다.
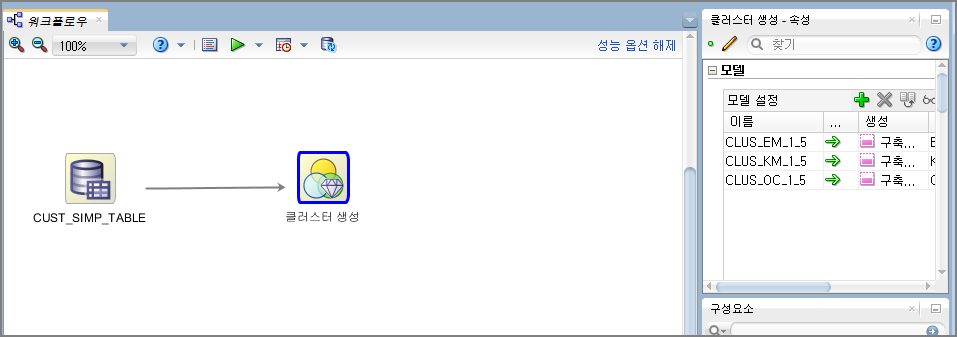
"클러스터생성" 아이콘을 클릭해보면 화면 오른쪽 [속성] 창에 모델 3개가 나타나는 것을 볼 수 있습니다.
(EM: Expectation Maximization, KM: K-Means, OC: O-Cluster)
특이한 것은, SQL*Plus 상에서 할때처럼 클러스터링 알고리즘을 선택한 후 분석을 시작하는게 아니고, 오라클에서 지원하는 클러스터링 알고리즘 3개(Expectation Maximization, K-Means, O-Cluster)에 대해 한꺼번에 클러스터링을 해버린다는 것입니다.
한꺼번에 돌려버릴테니 각 알고리즘에서 나온 결과를 보고 맘에 드는 걸로 골라서 쓰라는 식입니다. ㅋㅋ 완전 친절한 금자씨~~ 되겄심다. ㅋㅋ
만약, 특정 알고리즘만 실행하고 싶거나 제외하고 싶으면, 오른쪽 [속성] 탭에서 알고리즘 옆에 있는 초록색 화살표(->) 부분을 클릭해주면 해당 알고리즘을 제외하거나 실행에 포함하는 것이 조정가능합니다.
"클러스터생성" 아이콘에 마우스 오른쪽버튼을 클릭하고 팝업창에서 [편집] 메뉴를 클릭합니다.
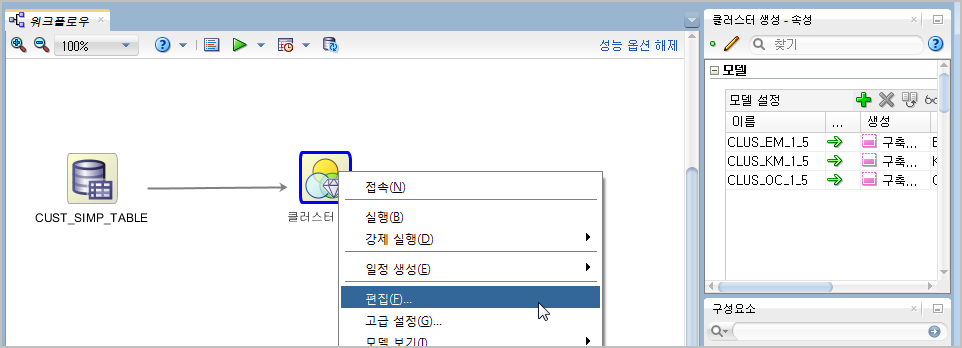
[편집]을 누르면 아래와 같은 편집창이 뜨는데, 여기에서 가장 중요한 것이 "사례 ID" 를 설정해주는 것입니다.
사례ID는 영어로는 Case ID 인데, 데이터를 유일하게 구분해주는 키정도로 생각하면 되겠습니다.
여기서 사용하는 CUST_SIMP_TABLE 테이블은 고객정보를 담고 있고, 사례ID는 고객을 구분하는 키인 CUST_ID 입니다.
사례ID 콤보박스를 클릭해서 CUST_ID를 선택해줍니다.
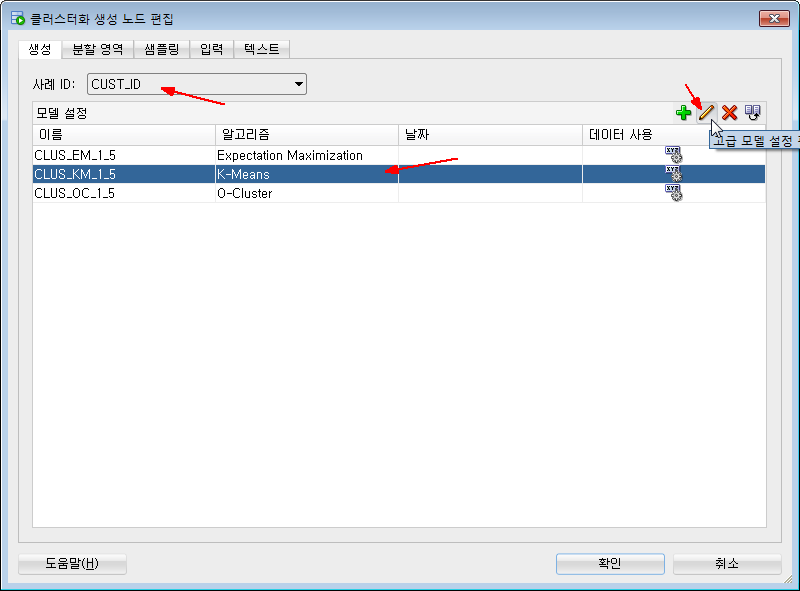
위와같이 사례ID만 선택해주고, [확인] 버튼을 눌러서 바로 클러스터링을 할 수 있습니다.
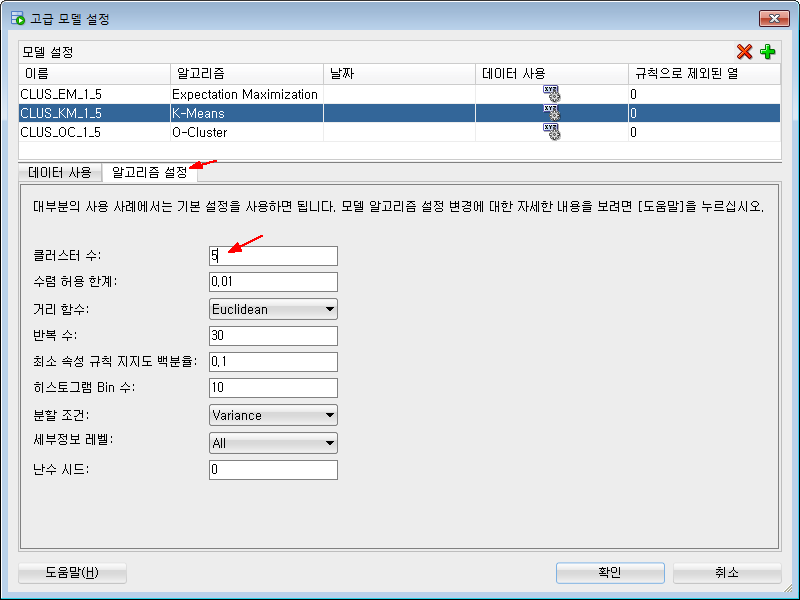
각 알고리즘별로 변경할 수 있는 세팅값들이 있는데, 이것을 수정하려면 각 알고리즘을 선택하고, 오른쪽 위에 있는 연필모양 아이콘을 클릭해주면 됩니다.
여기에서 다른 설정은 건드리지 말고 "클러스터 수" 만 10 -> 5 로 바꿔보겠습니다.
이렇게 바꾸면 최종 클러스터링을 5개로 만들게 됩니다.

3개 알고리즘 모두 [알고리즘 설정] 탭에서 "클러스터 수" 를 5로 바꿔줍니다.
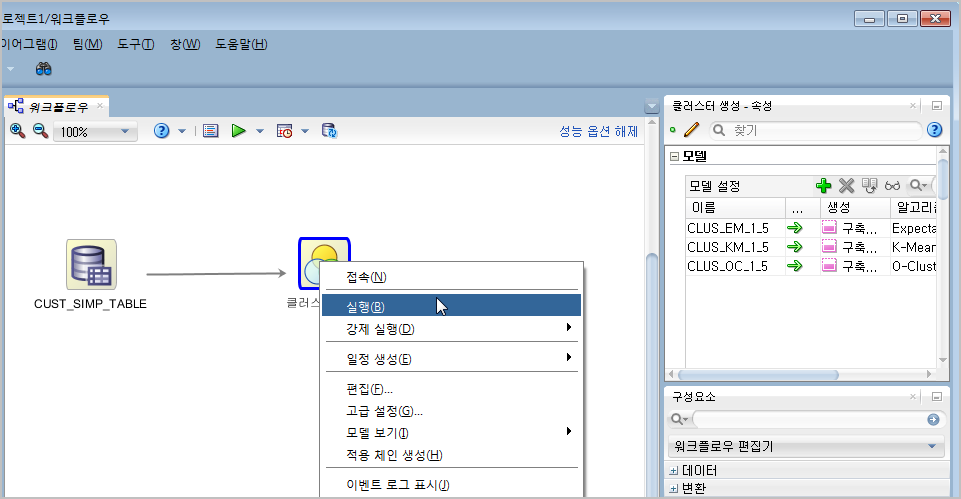
이제 클러스터링을 실행해 보겠습니다.
"클러스터생성" 아이콘에 마우스 오른쪽버튼을 클릭하고 팝업창에서 [실행] 메뉴를 누르면 클러스터링을 바로 실행합니다.
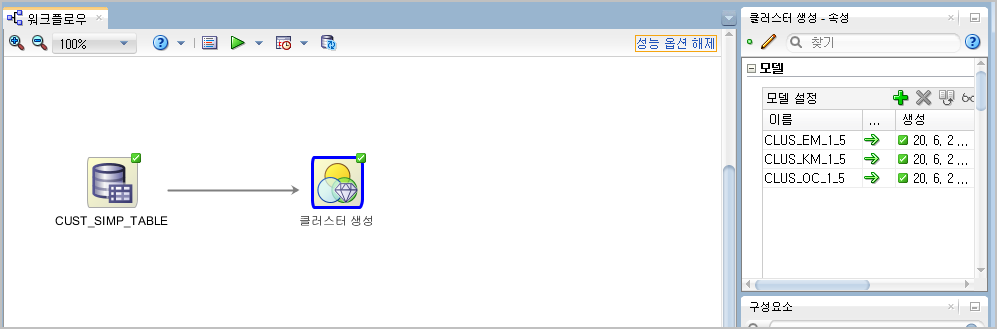
실행이 성공적으로 끝나면, 아래와 같이 각 아이콘 오른쪽위 귀퉁이에 v 자 마크가 나타납니다.
3) 클러스터링 학습결과 확인
"클러스터 생성" 아이콘에서 오른쪽 마우스버튼을 눌러 팝업창메뉴를 띄웁니다.
[모델보기] 메뉴를 클릭하면 알고리즘 3개가 나오는데, 각각을 눌러서 클러스터링된 결과를 확인할 수 있습니다.
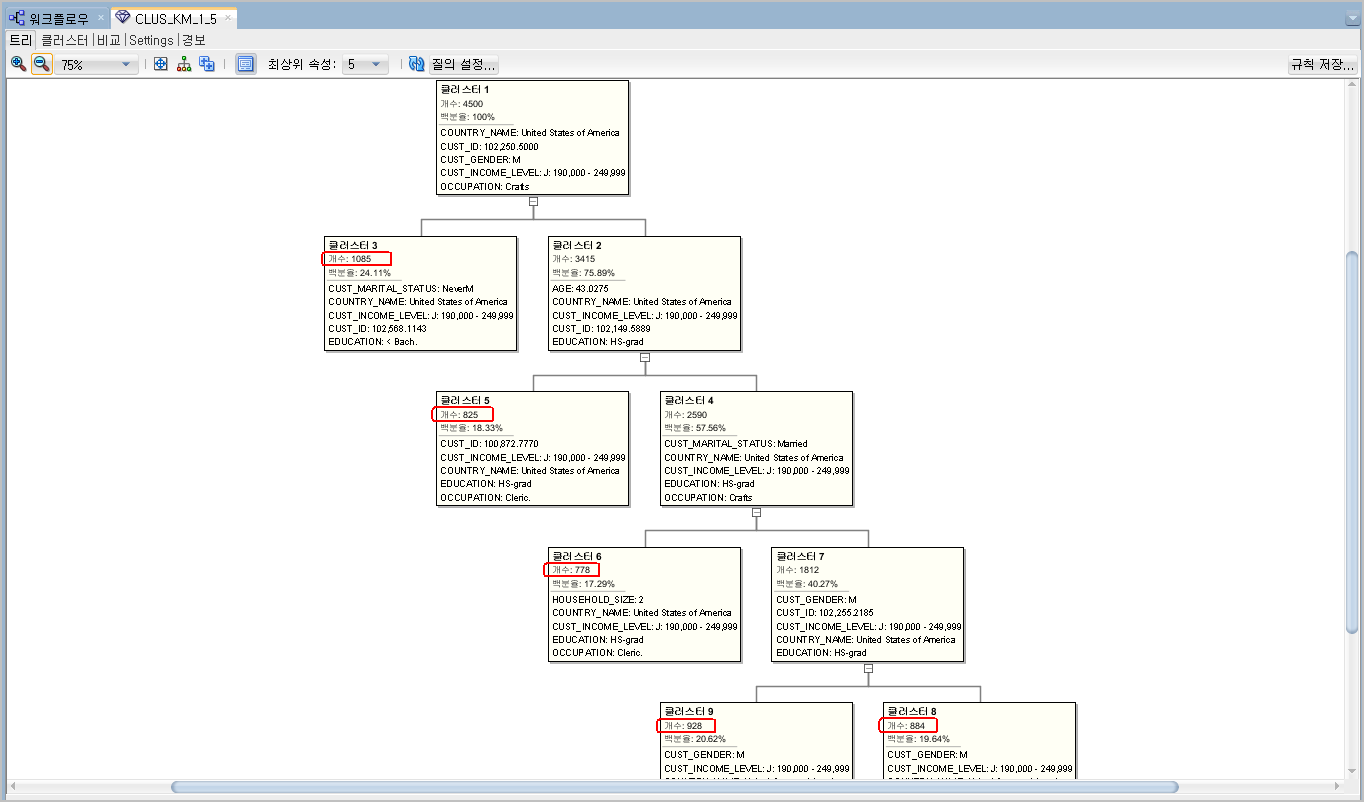
클러스터링결과를 트리형태로 도식화해서 보여 줍니다. 각 트리의 말단노드(Leaf node) 갯수가 우리가 지정한대로 5개로 되어 있는 것을 확인할 수 있습니다.
각각 몇건의 데이터가 해당 클러스터로 묶였는지 데이터갯수를 확인할 수 있고, 각 클러스터의 속성이 무엇인지 등의 정보를 한눈에 확인할 수 있습니다.
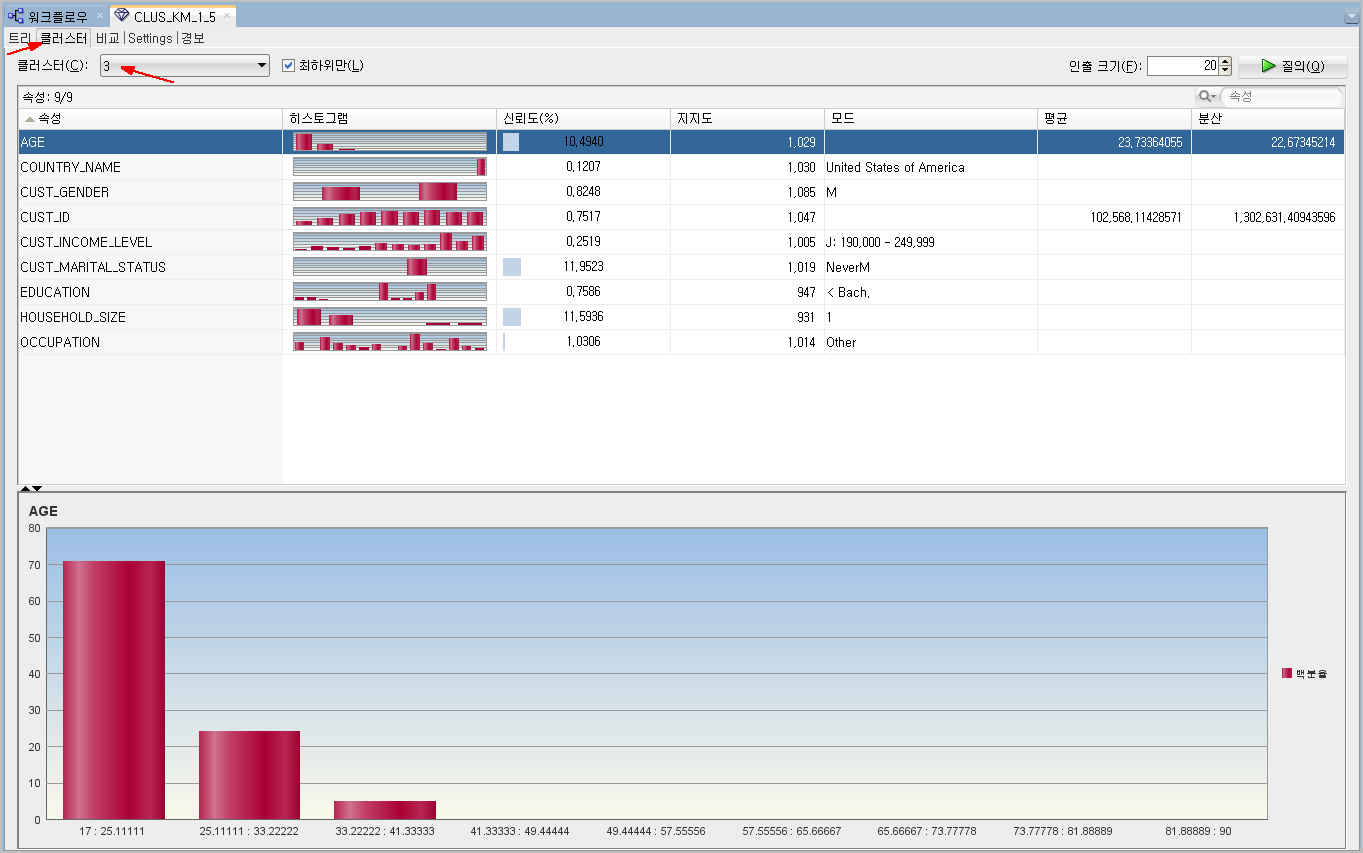
[트리] 탭 옆에 있는 [클러스터] 탭을 클릭하면, 각 클러스터별로 속성 분포도가 어떻게 되어있는지 그래픽컬하게 확인할 수 있습니다.
아래의 경우는 3번 클러스터에 대한 속성정보를 보여주고 있습니다.
아래는 O-Cluster 알고리즘으로 클러스터링한 결과 트리입니다.

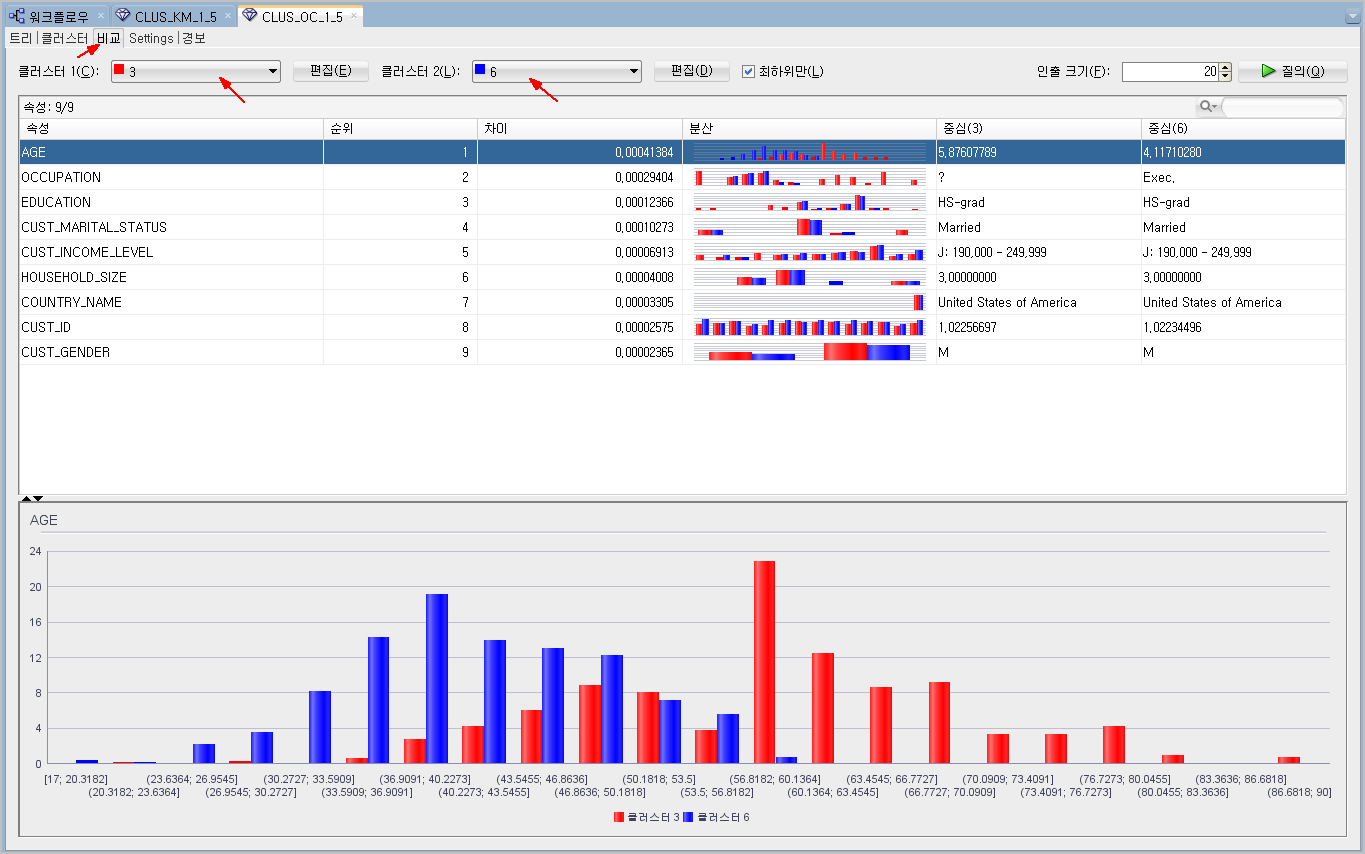
[클러스터] 탭 옆에 있는 [비교] 탭을 클릭하면 서로다른 2개의 클러스터를 비교해볼 수도 있습니다.
아래는 3번 클러스터와 5번 클러스터를 속성별로 서로 비교해서 보여주고 있습니다.
지난번 포스트에서 보여드렸듯이 SQL*Plus 상에서도 Machine Learning 이 가능하긴 하지만, 이런 부가적인 정보를 조회하는 경우를 생각하면, Data Miner 가 훨씬 편하고 좋은 것 같습니다.
여기까지 해서 Clustering 학습을 마친 것입니다.
이 학습된 정보(모델)을 바탕으로 실제로 적용(Apply) 하는 과정이 필요합니다. 이건 아래 링크에서 계속 됩니다.
참조 ==> >> SQL*Developer (Data Miner) 에서 클러스터링(Clustering) 실습 예제 2 (적용) <<
'IT관련' 카테고리의 다른 글
| 오라클 에러 정보 (ORA-40027) - 대상 속성에 고유 값이 두 개보다 많이 있습니다. (0) | 2020.06.03 |
|---|---|
| 오라클 머신러닝 - SQL*Developer (Data Miner) 에서 클러스터링(Clustering) 실습 예제 2 (적용) (0) | 2020.06.02 |
| 오라클 SQL*Developer 에서 머신러닝을 위한 Data Miner 이용하는 방법 (데이터마이닝 준비작업) (0) | 2020.06.01 |
| 오라클 DB Autotask 와 Maintenance Window - EM 화면에서 (0) | 2020.06.01 |
| 오라클 SQL*Developer 에서 테이블 Import/Export 하는 방법 (1) | 2020.05.27 |



